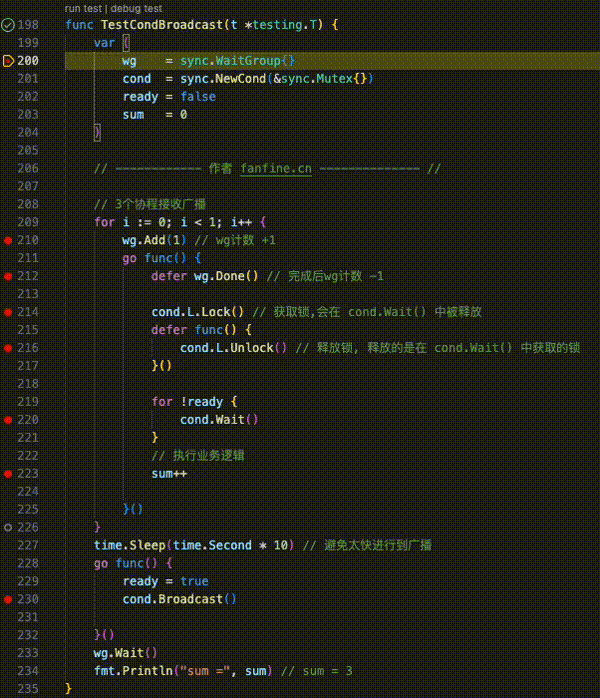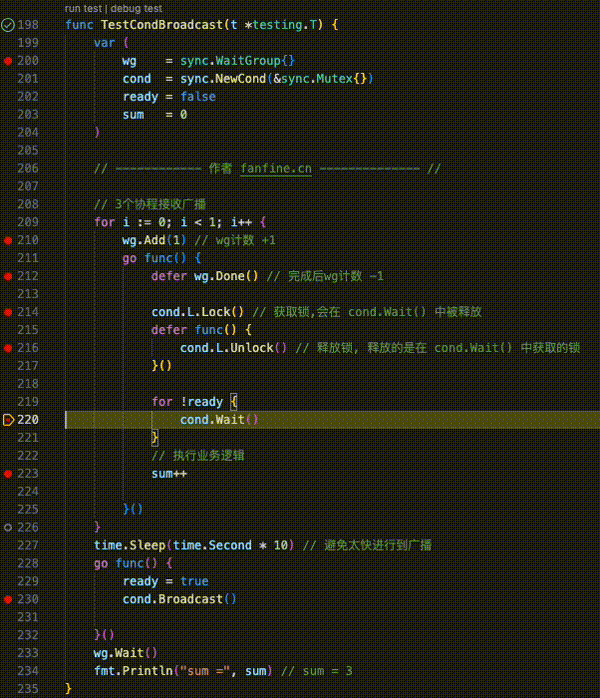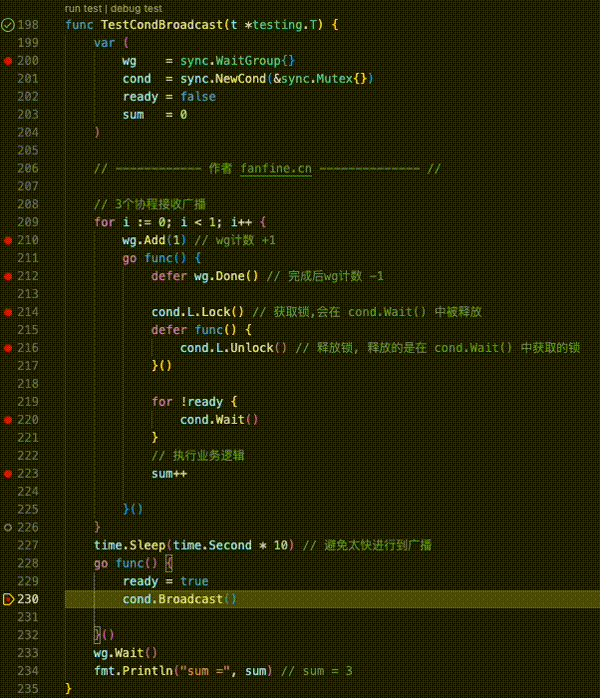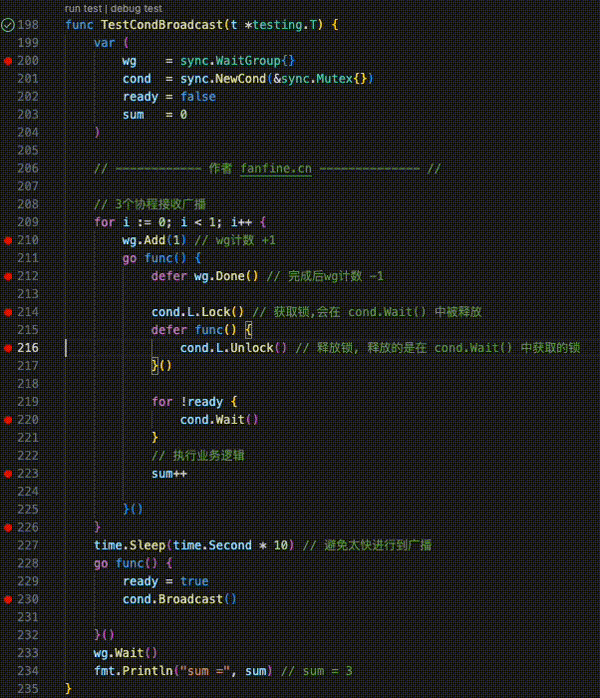
分布式缓存 - Redis集群 - 理论篇
单机Redis的承载能力毕竟是有限的,当单机无法承载大量并发,为了提高查询的效率,
可以采取集群的方式,将多个redis实例组成集群。
关键词
- 缓存击穿
- 缓存雪崩
- 主从复制
- 切片模式
- 分布式锁
缓存击穿
缓存击穿是指,当缓存失效时,大量请求同时到达数据库,导致数据库压力过大。
id过滤器
当有人大量访问任意id,但是缓存中不存在,就会去访问数据库,其实数据不存在,但是客观的占用了数据库资源。也就是缓存击穿
那么可以通过增加id过滤器,就是对id进行过滤,如果过滤器的出数据存在,就直接返回,不在就访问数据库。避免缓存击穿。
但是内存中不可能存储所有id的存在情况,如果数据量过大,就会占用大量内存。
所以可以使用 布隆算法,
通过错误率换取空间的占用
算法表示数据存在 就去查数据库,但实际不一定存在,但没关系,对mysql的访问量已经削弱了。
算法表示数据不存在,实际一定不存在
创建一个 bit 数组,每个位置对id进行hash计算.
缓存雪崩
出现雪崩的情况:
- 如果redis全部挂掉,
全去查mysql了,大量的请求直接怼到mysql,导致数据库压力过大,很可能会导致宕机。 - 缓存失效时间设置过短,
导致缓存失效,可以对热数据随机设置有效期,让大量数据不会在同一段很短的时间内失效。
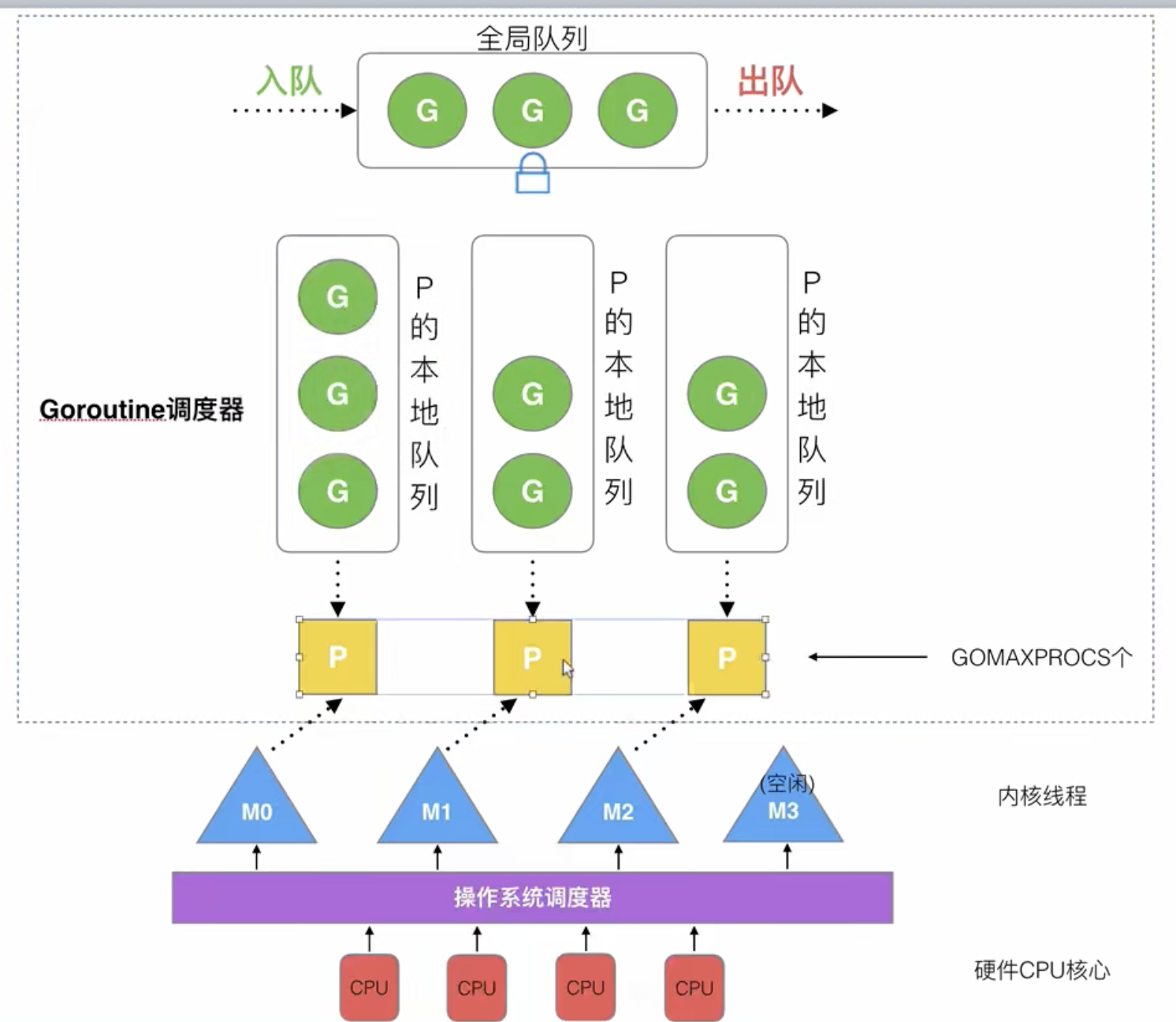
主从复制
解决单点故障问题的,
数据同步节点间,数据是全量的。
若主库挂了,一个从库升级为主库,
主库和从库是独立的,主库负责写,同步到从库,从库负责读。
master 主库
slave 从库
需解决的问题
- 主从复制,数据一致性问题,同步数据不精准。
- 同步延迟问题。
- 主从复制的方式并不能解决数据量过大的问题,单机不能无限制纵向扩容。
而需采用横向扩展的方式,也就引出切片模式
切片模式
分治,分片的,解决容量压力、容量平静问题
每个节点存储的是一部分数据
切片规则一(不可使用,是思考的过程)
对 key 进行 hash ,然后取模 ,
假设有2台服务器上,那么取模的结果范围为 [0,1]
hash(key) % 2 == 0 放到一个 redis 实例上,
hash(key) % 2 == 1 放到另一个 redis 实例上。
存在的问题
- 增减 redis 服务器数量
- 取模结果范围增大或减小,原属于其他 redis 服务器部分的 key 需要迁移,
因为对key 取模的规则发生了变化,结果不一致,所以需要迁移。 - 所有的 redis 实例都需要参与数据迁移
- 取模结果范围增大或减小,原属于其他 redis 服务器部分的 key 需要迁移,
这个办法没法满足动态增加和减少 redis 服务器的需求。
所以不能用这种方法
一致性Hash算法
hash环
想象一个环,环上每个节点对应一个redis实例可以存放的位置。
以下对环上的位置称为“节点”
在golang中可以定一个一个结构体
type HashRing struct {
Node uint // 节点编号(文章来自 fanfine.cn)
NextNode uint // 下一个节点的编号
}当节点为最大数值时,他的下一个节点 NextNode 为数值最小的节点的数值。
以此形成一个环形。
redis 实例在环上的节点
redis 实例在环上节点计算方式为 redis 实例的IP地址+编号 hash计算 然后取模 2^32。
redis 实例在环上的节点 = hash(ip+编号) % 2^32环上数据存储
数据key的节点 = hash(key) % 2^32顺时针找到距离该节点的下一个最近的 redis实例的节点,然后把数据放到该redis实例上。
举例
对集群的扩展和缩减非常有利,比如:
现在在环上按照顺序有 1 2 3 4 共 4 个 redis 实例的节点,注意这 1,2,3,4 是个环形,所以4的下一个位置是1;
- 增加了 redis 实例5 ,其节点在 原来的 4 和 1 之间,那么key节点在 4 和 5之间,
原本存储在1的那部分数据,需要迁移到5上,5-1之间的数据不变仍保留在1上。 - 删除了 redis 的实例4 ,那么原本 数据 key 取模节点原来在 3 和 4 之间,存储在4上的数据,需要迁移到 1 上。
如此,当发生 redis 实例增减的时候,仅需迁移一台 redis 实例上的数据,而不需要对所有redis实例进行迁移。
存在的问题
- 数据倾斜
即大部分的数据,存储在少量的 redis 实例上,
当多个 redis 实例的节点非常接近时,hash环上会有大量空闲位置,导致数据倾斜到某一个redis实例上。
而在hash环的短弧的部分,因为节点数量少,所以存储在另一个redis实例上的数据量也少。
解决办法:
增加更多的虚拟redis实例,并计算节点,使节点在 hash环上分布更均匀。
并将其映射到 真实的 redis 实例上。
比如我有2个redis 实例,那么每台redis实例都有2个虚拟节点,这样节点分布更均匀。
当然仍会有倾斜,但是倾斜程度会降低。可以增加更多虚拟节点,使节点分布更均匀。
redis 分布式锁
关键词
- setnx + timeout
- 删除自己
- 有效期延迟
- 主从问题
- 延迟启动
- RedLock:Redis Lock的缩写。
思路
-
client1 获取到了锁:setnx + timeout
-
client2 没有抢到锁,进入自旋,循环的 setnx 以求获得锁,(当然可以设置自旋时间或自旋次数)
此时如果还有非常多的 client 像 client2一样没有抢到锁,陷入自旋,就会有大量的 setnx 请求,造成网络io的浪费。
使用 redis的发布订阅(阻塞队列) 即 抢到锁的 client1 发布,没有抢到锁的 client2 之流订阅,在接收到后,才 setnx
以此避免 自旋的过程中发生大量的无效的网络io。 -
如果client1程序活着,处理完任务后释放锁,其他client 自旋可以抢到锁,
但若client1程序挂了,1的锁在 timeout 后也会释放,其他 client 自旋也可以抢锁。 -
client1 没有挂,但是执行时间超过了timeout,锁会释放,其他 client 自旋可以抢到锁,此时会有 client1 和其他的 client 都抢到锁,并修改公共数据,发生数据竞争
解决办法:
看门狗监控,若client1任务没有完成,在原锁超时释放前,给锁续命, -
redis也有可能会挂
主从复制中,redis主库挂了,从库会顶上称为新的主库
但是主库中的锁没有同步到从库,(这是一个数据一致性问题,也许是同步速度问题,也许是同步精度问题)
那么切换到从库后,其他client可以抢到锁了,
此时client1、另一个在新主库抢到锁的client ,都修改了公共数据,发生数据竞争。
那么怎么解决这个问题?
有的大厂某部门的分布式锁,用的一台redis实例,没有主从复制
红锁 redlock
选举制的思想,
是client实现的
多台redis实例,更多的client,
client需要修改公共数据的时候,向多台分布式锁的redis实例发送获取锁请求,
只有当在超过半数的redis实例上取得锁,才算是取得了锁,才能修改公共数据。
如果恰好3台client,3台redis实例,
每个client都只在其中一台redis实例取得锁,那么都不是超过半数,那么就需要随机睡眠一会,再重新抢锁。
听着性能就不太行,
这是建立在我们极度渴望redis单机挂了,不会出现数据竞争的基础上。
同样也要做。