Goroutine
Goroutine 的基本概念
Goroutine:协程,是轻量级的线程,由 GMP调度器 运行时管理。
基本使用
go func()
Goroutine 的栈大小
默认栈大小:
Go 语言中,默认的 goroutine 栈大小为 2KB。
这个大小是为了适应大多数简单函数调用的需求。
动态增长和收缩:
goroutine 的栈大小可以动态增长和收缩。
当 goroutine 需要更多内存时,栈会自动增长;当不再需要那么多内存时,栈会自动收缩。
协程间数据传递
协程间通过 channel 可以在 goroutine 之间传递数据。
下面是一个使用 channel 在 goroutine 之间传递数据的例子。
第一个goroutine 向 channel 中写入数据,
第二个goroutine 从 channel 中读取数据,并打印出来。
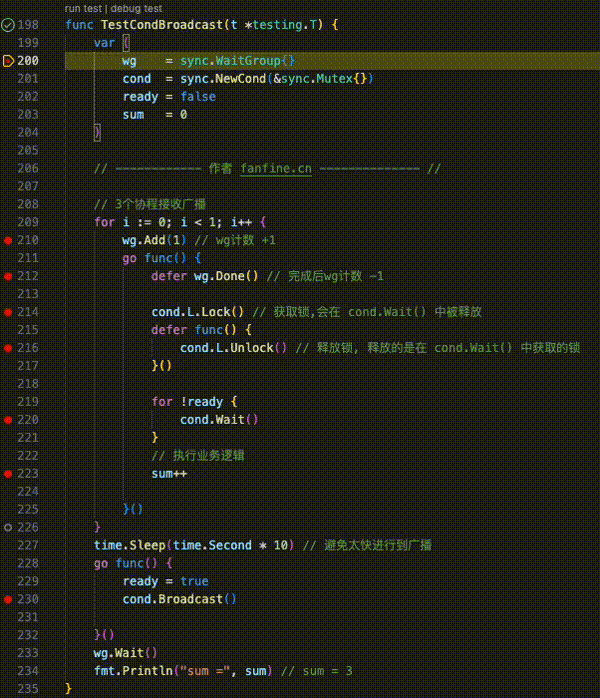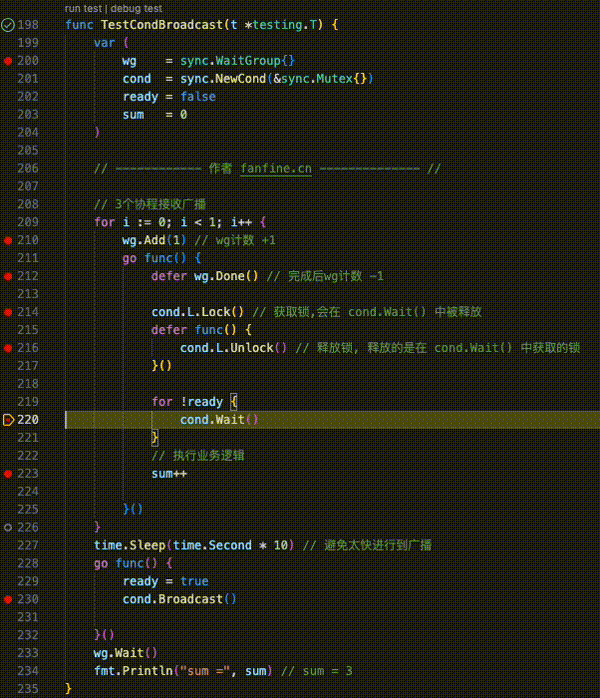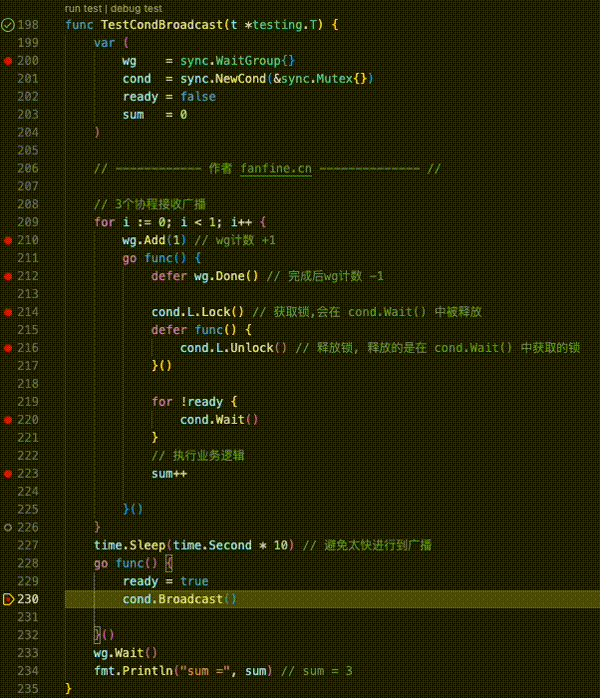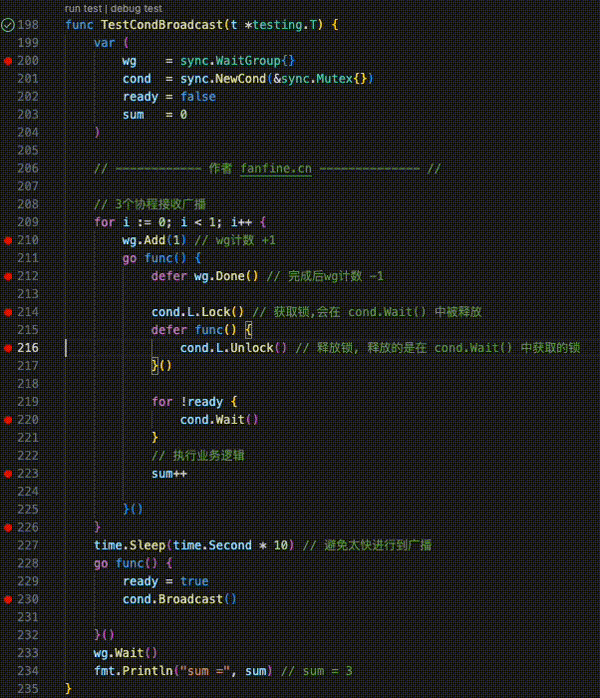
func TestGoroutineChannel(t *testing.T) {
ch := make(chan int, 10)
wg := sync.WaitGroup{}
wg.Add(1)
// channel 被写入
go func() {
defer wg.Done()
for i := 0; i < 10; i++ {
ch <- i
}
close(ch)
}()
// channel 被读取
wg.Add(1)
go func() {
defer wg.Done()
for {
data, ok := <-ch
if !ok {
fmt.Println("channel 关闭")
break
}
fmt.Println("接收到:", data)
}
}()
wg.Wait()
fmt.Println("over !")
}GMP模型
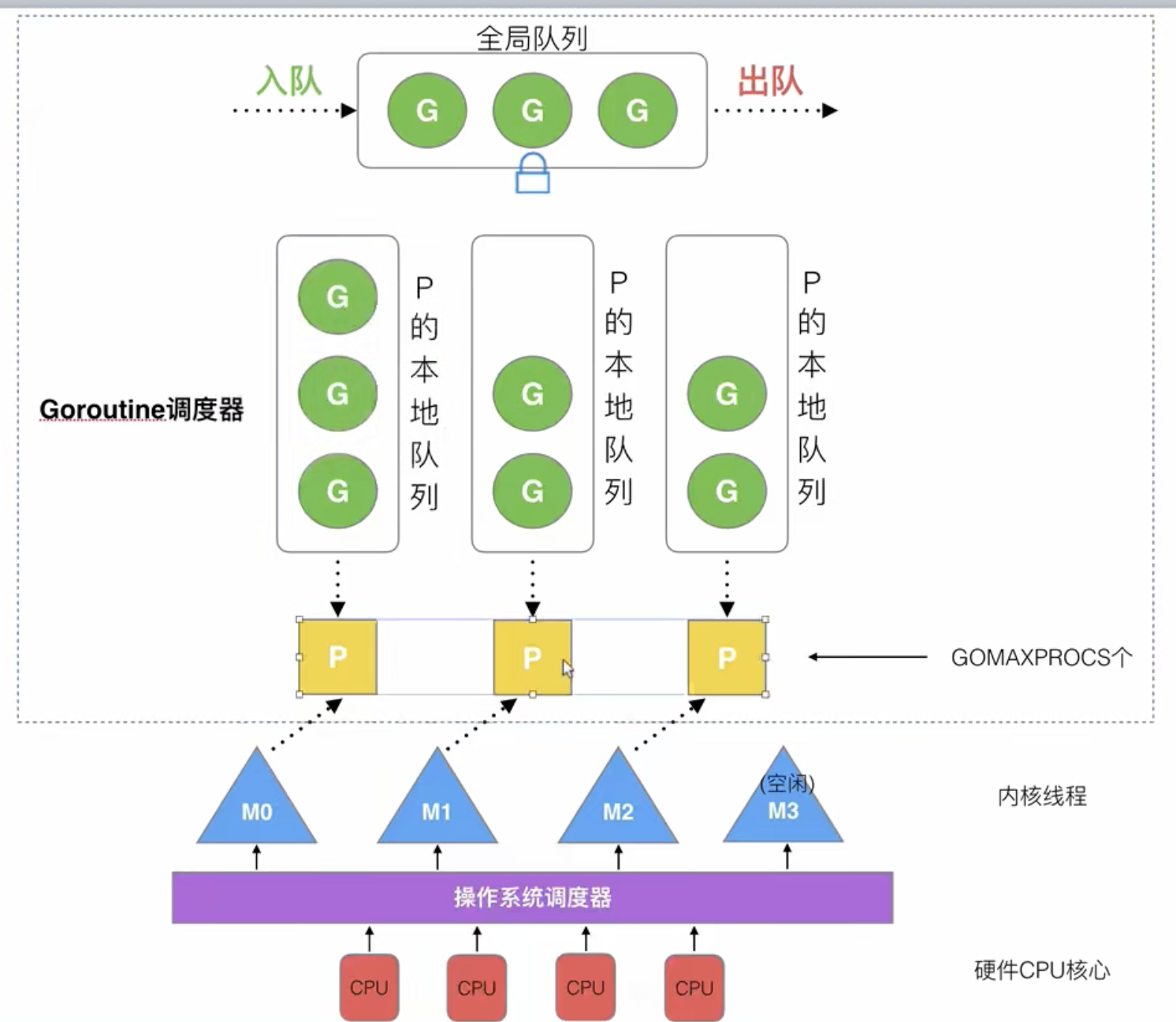
简介
-
G 协程
goroutines -
M 内核线程
thread -
P 处理器
processer -
全局队列
- 存放等待运行的G
-
P的本地队列
- 存放等待运行的G
- 有数量限制,一般不超过256个协程
goroutine - 优先将新的G放到P的本地队列,如果满了,就放到全局队列
-
P列表
- 程序启动时创建
- 最多GOMAXPROCS个,作为环境变量,可以配置
-
M列表
- 当前操作系统分配的内核线程数
-
P的数量
- P的数量决定了同一时刻只能有P数量的G运行,和宏观的并发量有点区别
- 环境变量配置 GOMAXPROCS
- 使用runtime.GOMAXPROCS()设置
-
M的数量问题
- GO系统本身,限定对M最大量为10000,但是实际上单机通常跑不了那么多线程
- 使用runtime/debug包的SetMaxThreads设置
- 又一个新的M阻塞,会创建新的
- 如果M空闲会被回收
深入理解
调度器的设计策略
work stealing机制
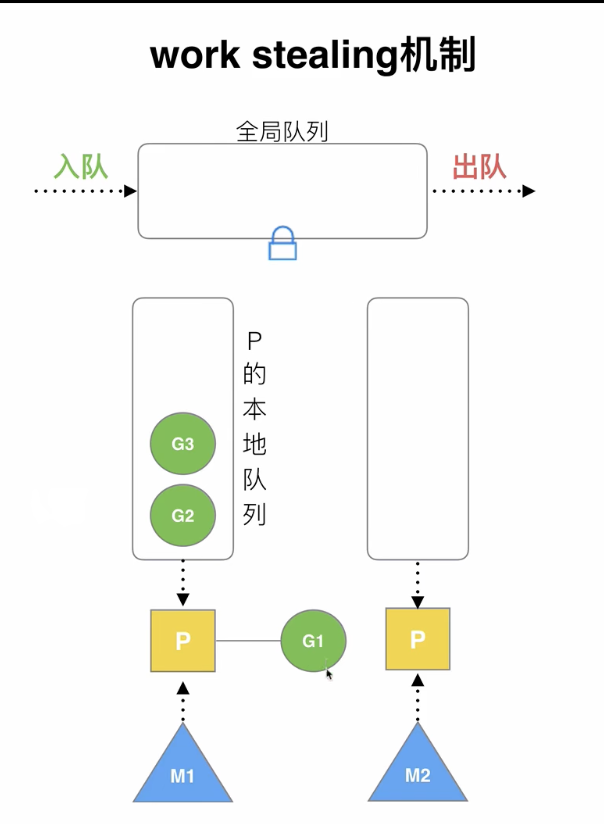
当一个P的本地队列中有多个G,另一个P空闲,则空闲P会偷取一个G去运行
hand off机制
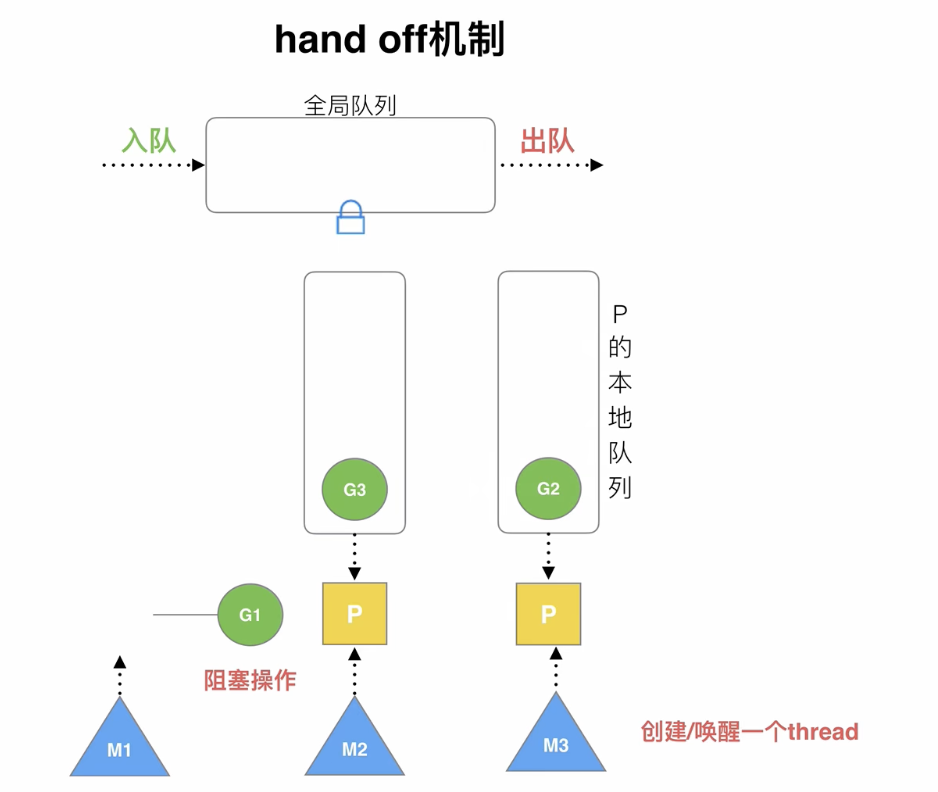
P1正在运行的G1在M1上运行,发生阻塞时,
会创建或唤醒另一个thread M3,
P1的本地队列会安排到M3上运行,
发生阻塞的G1继续在M1上执行,避免G2被耽误,
如果G1后续不再执行,M1会被销毁或睡眠,G1都会被销毁
G1需要继续执行的话,G1会被放入全局队列中,等待被安排到P的本地队列中
抢占
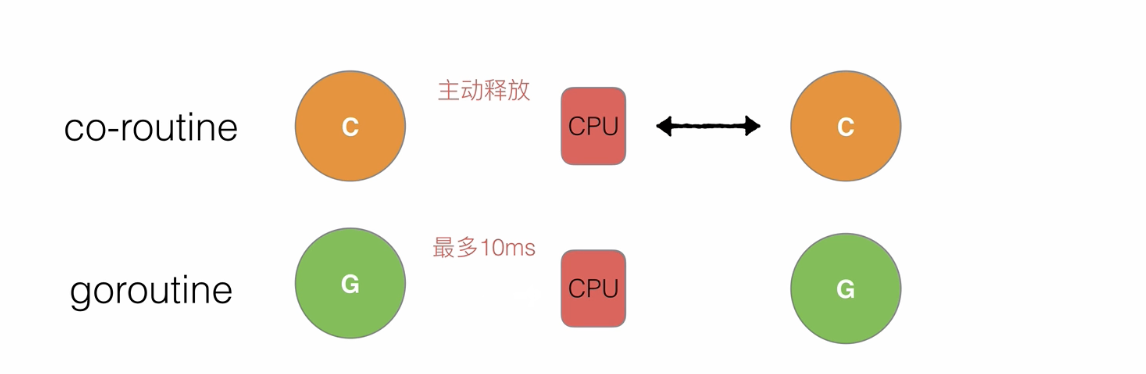
一个goroutine在运行,阻塞超过10ms时,其他等待中的G会抢占CPu去执行,
全局G队列
空闲P先以Work Stealing机制从别的P本地队列中偷取G,若无,则从全局G队列中取G运行局部性
为了局部性,G1创建的G3,优先加入G1所在的P的本地队列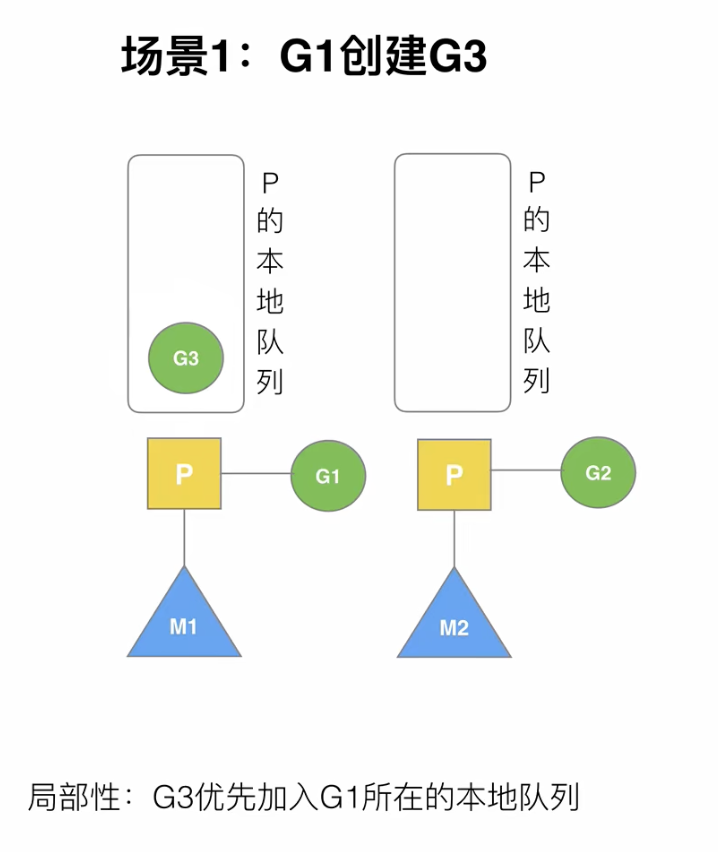
G 切换
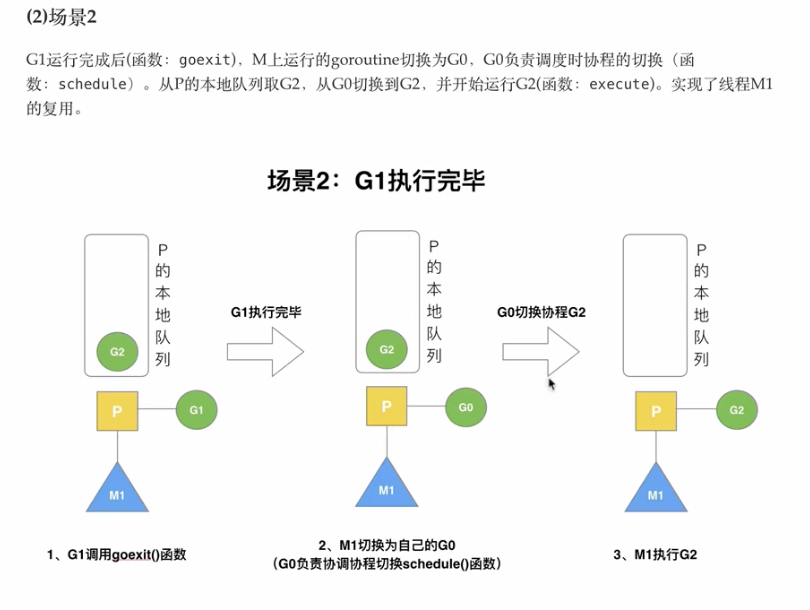
其他
GOMAXPROCS限定P的个数可以控制,比如可以为
= CPU核数/2GO 指令的调度流程
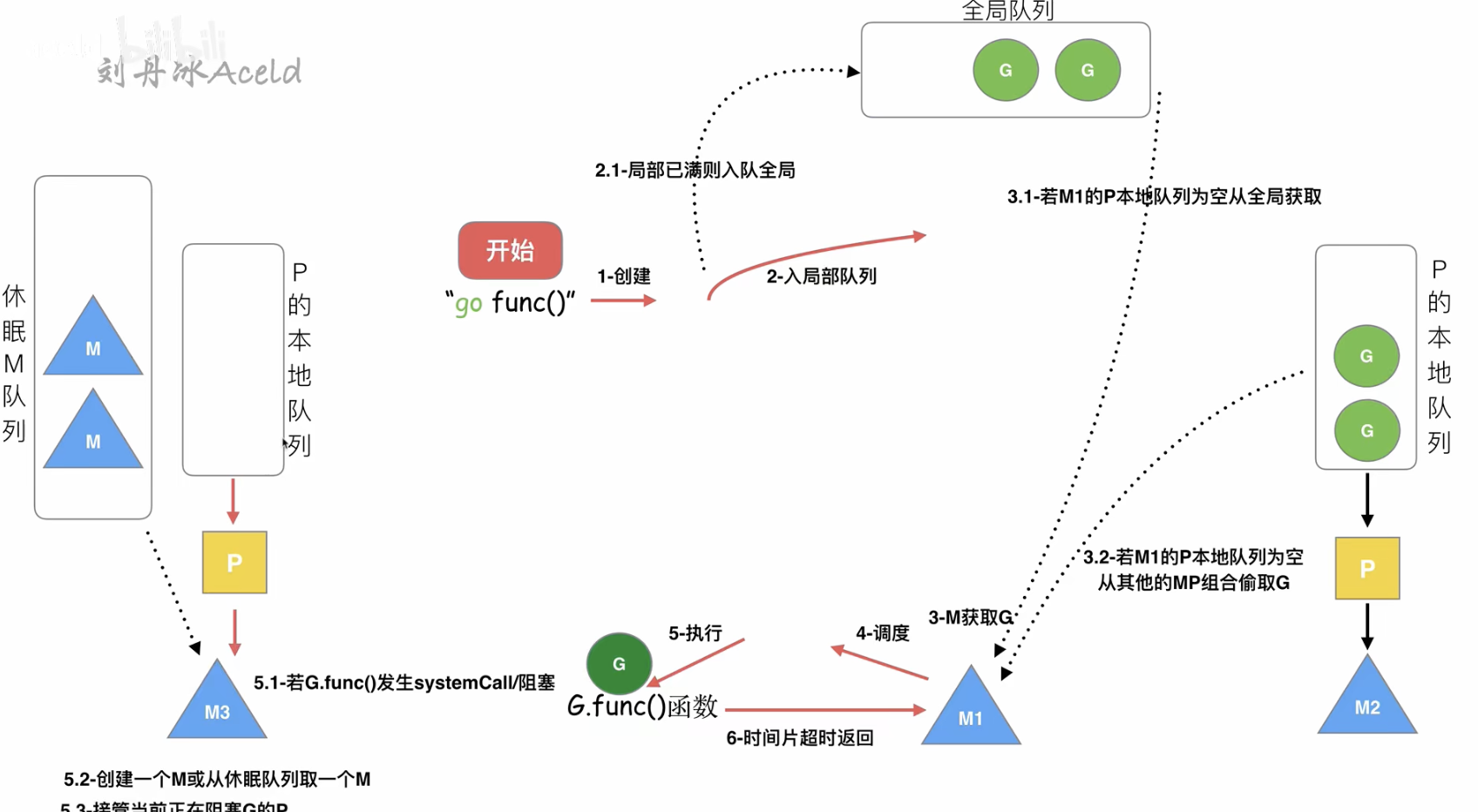
- 通过go func()创建一个G
- 有两个存储G的队列,一个是局部调度器P的本地队列,一个是全局G队列.新创建的G会先保存在P的本地队列中,如果P的本地队列已经满了就会保存在全局队列中
- G只能运行在M中,一个M必须持有一个P,M与P是1:1的关系.M会从P的本地队列弹出一个可执行状态的G来执行,如果P的本地队列为空,就会想其他的MP组合头去一个可执行的G来执行
- 一个M调度G执行的过程是一个循环机制
- 当M执行某一个G时如果发生了syscall或者其他阻塞操作,M会阻塞,如果当前有一些G再执行,runtime会把这个M从P中摘除,会创建一个新的M,如果有空闲的线程可用就复用这个新的M,来服务这个P
- 当M调用结束时,这个G会尝试获取一个空闲P执行,并放入P的本地队列,如果获取不到P,这个M会变成休眠状态,加入空闲线程中,然后这个G会放到全局队列中
调度器的生命周期
M0
启动程序后的编号为0的主线程
在全局变量runtime.m0中,不需要在heap上分配
负责执行初始化操作和启动第一个G
启动第一个G之后,M0就和其他M一样了
G0
每次启动一个M,都会第一个创建的Goroutine,就是G0
G0是仅用于负责调度的G
G0不任何可以执行的函数
每个M都会有一个自己的G0
在调度或系统调用时,会使用M切换到G0来调度
M0的G0会放在全局空间
可视化GMP编程
基本的trace编程
低版本
运行程序使用下面的指令:
go run -trace=trace.out main.go
运行后会得到一个trace.out文件
使用 go tool trace trace.out 打开trace文件
访问网站即可在浏览器上查看
go tool trace trace.out
2024/03/02 09:57:18 Parsing trace...
2024/03/02 09:57:18 Splitting trace...
2024/03/02 09:57:18 Opening browser. Trace viewer is listening on http://127.0.0.1:59146
如果你的go版本较高
我的本地go版本为1.22.4
使用上述指令时会出现报错:flag provided but not defined: -trace
可以使用以下方法,手动生成 trace.out 文件。
运行 go run main.go 即可。
然后可以在目录下看到 trace.out 文件了。
go tool trace trace.out
2024/09/14 20:49:30 Preparing trace for viewer...
2024/09/14 20:49:30 Splitting trace for viewer...
2024/09/14 20:49:30 Opening browser. Trace viewer is listening on http://127.0.0.1:52350
import (
"fmt"
"os"
"runtime/trace"
"sync"
"time"
)
func main() {
var wg sync.WaitGroup
// 启动 trace
traceFile := "trace.out"
f, err := os.Create(traceFile)
if err != nil {
panic(err)
}
defer f.Close()
err = trace.Start(f)
if err != nil {
panic(err)
}
defer trace.Stop()
// 添加任务
for i := 0; i < 5; i++ {
wg.Add(1)
go func(id int) {
defer wg.Done()
fmt.Printf("Goroutine %d started\n", id)
time.Sleep(time.Second)
fmt.Printf("Goroutine %d finished\n", id)
}(i)
}
// 等待所有 Goroutine 完成
wg.Wait()
fmt.Println("All Goroutines finished")
}
在浏览器中查看 trace 记录
用以上方法,可以看业务运行时会开启多少G,有多少M
可以用来看高峰期会有多少G
通过GMP的可视化,分析负载
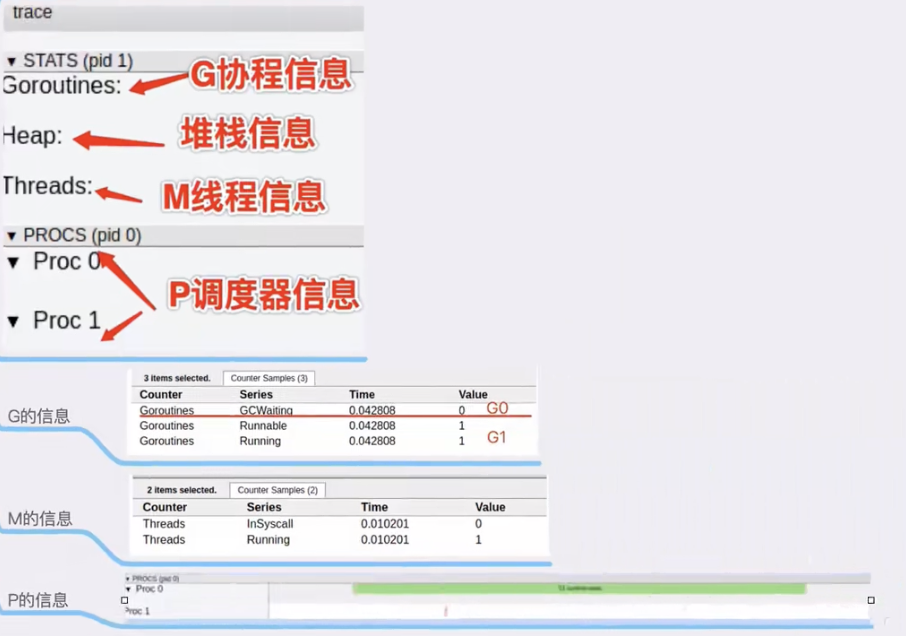
GMP终端DEBUG调试
通过debug trace 查看gmP信息
GODEBUG=schedule=1000 ./可执行程序
GODEBUG=schedtrace=1000 ./build_main
SCHED 0ms: gomaxprocs=8 idleprocs=5 threads=5 spinningthreads=1 idlethreads=0 runqueue=0 [1 0 0 0 0 0 0 0]
hello gmp!
SCHED 1010ms: gomaxprocs=8 idleprocs=8 threads=5 spinningthreads=0 idlethreads=3 runqueue=0 [0 0 0 0 0 0 0 0]
hello gmp!
SCHED 2021ms: gomaxprocs=8 idleprocs=8 threads=5 spinningthreads=0 idlethreads=3 runqueue=0 [0 0 0 0 0 0 0 0]
hello gmp!
SCHED 3031ms: gomaxprocs=8 idleprocs=8 threads=5 spinningthreads=0 idlethreads=3 runqueue=0 [0 0 0 0 0 0 0 0]
hello gmp!
SCHED 4032ms: gomaxprocs=8 idleprocs=8 threads=5 spinningthreads=0 idlethreads=3 runqueue=0 [0 0 0 0 0 0 0 0]
hello gmp!
-
SCHED:
调试的信息 -
0ms
从程序启动到输出经历的时间 -
gomaxprocs
P的数量 一般默认和CPU的核心数量一致 -
idleprocs
处理idle状态的P的数量,gomaxprocs - idleprocs=目前正在执行的p的数量 -
threads
线程数量,包括M0,包括GODEBUG调试的线程 -
sniningthreads
处于自选状态的thread数量 -
idlethreads
处理idle状态的thread数量 -
runqueue
全局G队列中的G的数量 -
[0 0 0 0 0 0 0 0 ]
每个P的本地队列中,目前存在的G的数量